GD1
直接搜索GD逆向,发现是Godot引擎的简称,于是在github上找到逆向该引擎的工具
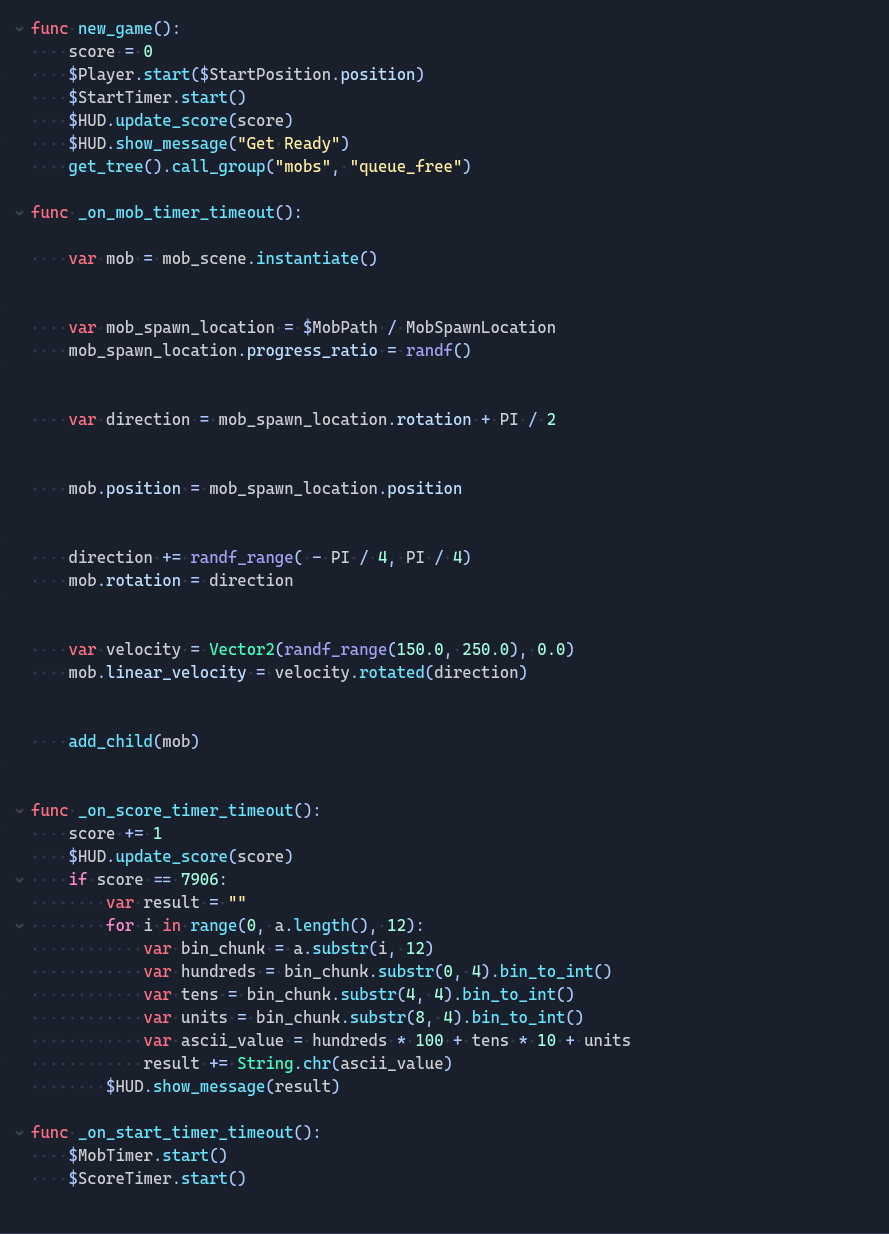 发现分数到7906的时候会触发什么东西,于是试一试。使用cheat engine找到分数的内存然后修改(可以直接写逆向脚本的,因为一开始没注意godot引擎,所以用CE改高分看能不能获得flag,最后还是用CE收尾吧)
发现分数到7906的时候会触发什么东西,于是试一试。使用cheat engine找到分数的内存然后修改(可以直接写逆向脚本的,因为一开始没注意godot引擎,所以用CE改高分看能不能获得flag,最后还是用CE收尾吧)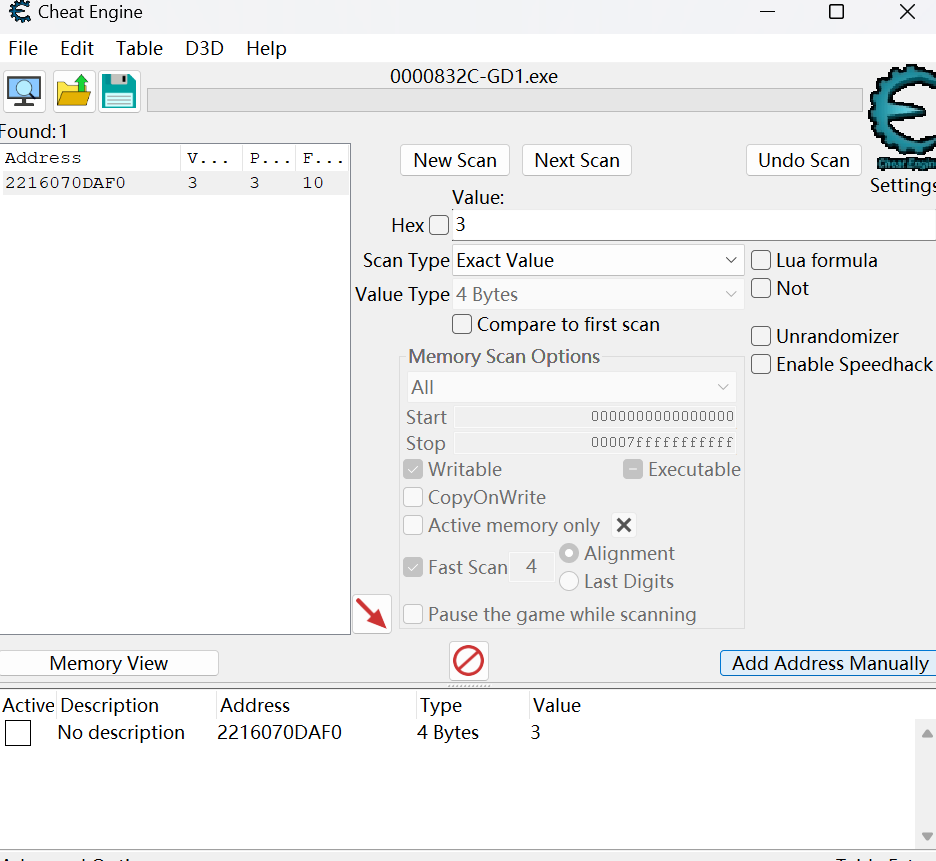

plus
首先运行一下python,发现是让我们输入flag,然后验证。
先写一个脚本把int里的值全加起来,不然太大了不好分析。
from init import *;m(exec(exit(int(307) + int(922) + int(928) + int(883) + int(0) + int(60) + int(32))),exit(int(167) + int(772) + int(16)),exit(int(209) + int(715) + int(2)))(e);m(exec(exit(int(307) + int(922) + int(928) + int(883) + int(0) + int(60) + int(32))),exit(int(188) + int(743) + int(68)),exit(int(655) + int(36)))(e);m(exec(exit(int(201) + int(800) + int(370) + int(677) + int(125) + int(856) + int(982) + int(9))),exit(int(167) + int(772) + int(16)),exec(exit(int(215) + int(430) + int(820) + int(910) + int(458) + int(736) + int(505) + int(0) + int(51) + int(870) + int(224) + int(350) + int(847) + int(782) + int(563) + int(842) + int(941) + int(767) + int(450) + int(663) + int(266) + int(900) + int(616) + int(936) + int(594) + int(409) + int(721) + int(828) + int(862) + int(0) + int(50) + int(250) + int(877) + int(0) + int(0) + int(7) + int(259) + int(502) + int(951) + int(573) + int(354) + int(763) + int(0) + int(39) + int(390) + int(911) + int(514) + int(251) + int(779) + int(543) + int(944) + int(934) + int(960) + int(684) + int(0) + int(0) + int(8) + int(209) + int(628) + int(473) + int(304) + int(218) + int(610) + int(967) + int(519) + int(892) + int(397) + int(440) + int(123) + int(955) + int(636) + int(948) + int(631) + int(0) + int(47) + int(774) + int(533) + int(721) + int(835) + int(838) + int(0) + int(86) + int(0) + int(12) + int(898) + int(766) + int(274) + int(946) + int(831) + int(732) + int(554) + int(223) + int(371) + int(869) + int(0) + int(0) + int(7) + int(493) + int(373) + int(0) + int(65) + int(194) + int(188) + int(0) + int(38) + int(0) + int(55) + int(945) + int(3))),)(e);m(exec(exit(int(211) + int(0) + int(23) + int(573) + int(828) + int(994) + int(606) + int(397) + int(3))),exit(int(44)),exit(int(189) + int(399) + int(0) + int(3)))(e);m(exec(exit(int(201) + int(800) + int(370) + int(677) + int(125) + int(856) + int(982) + int(9))),exit(int(188) + int(784) + int(64)), i(exec(exit(int(520) + int(485) + int(229) + int(507) + int(545) + int(392) + int(928) + int(716) + int(380) + int(743) + int(873) + int(332) + int(979) + int(750) + int(615) + int(584)))).encode())(e);m(exec(exit(int(211) + int(0) + int(23) + int(573) + int(828) + int(994) + int(606) + int(397) + int(3))),exit(int(39)),exit(int(188) + int(784) + int(64)))(e);m(exec(exit(int(211) + int(0) + int(23) + int(573) + int(828) + int(994) + int(606) + int(397) + int(3))),exit(int(43)),exit(int(44)))(e);m(exec(exit(int(211) + int(0) + int(23) + int(573) + int(828) + int(994) + int(606) + int(397) + int(3))),exit(int(40)),7)(e);m(exec(exit(int(187) + int(100) + int(846) + int(671) + int(655) + int(242) + int(610) + int(0) + int())), exit(int(167) + int(772) + int(16)), exit(int(167) + int(773) + int(32)))(e);p(exec(exit(int(173) + int(535) + int(626) + int(0) + int()))) if (b(m(exec(exit(int(788) + int(282) + int(697) + int(949) + int(0) + int(48) + int(867) + int(6))), exit(int(188) + int(784) + int(64)), exit(int(44)))(e)).decode()== exec(exit(int(636) + int(496) + int(797) + int(464) + int(929) + int(889) + int(819) + int(0) + int(18) + int(589) + int(958) + int(474) + int(261) + int(894) + int(226) + int(380) + int(884) + int(858) + int(896) + int(837) + int(0) + int(50) + int(849) + int(823) + int(120) + int(0) + int(96) + int(559) + int(828) + int(809) + int(884) + int(712) + int(107) + int(801) + int(783) + int(610) + int(237) + int(788) + int(137) + int(0) + int(0) + int(2) + int(972) + int(622) + int(711) + int(849) + int(132) + int(377) + int(866) + int(432) + int(975) + int(817) + int(0) + int(21)))) else p(exec(exit(int(310) + int(844) + int(326) + int(706) + int(854) + int(73)))) #type:ignore一般来说int(1)+int(2)=3于是把这些全取消了,但是发现运行不了了提示需要str,于是想到int可能是将整数转换为字符串,于是"1"+"2"="12"
from init import *;
m(exec(exit("30792292888306032")), exit("16777216"), exit("2097152"))(e);
m(exec(exit("30792292888306032")), exit("18874368"), exit("65536"))(e);
m(exec(exit("2018003706771258569829")), exit("16777216"), exec(exit("2154308209104587365050518702243508477825638429417674506632669006169365944097218288620502508770072595029515733547630393909115142517795439449349606840082096284733042186109675198923974401239556369486310477745337218358380860128987662749468317325542233718690074933730651941880380559453")))(e);
m(exec(exit("2110235738289946063973")), exit("44"), exit("18939903"))(e);
m(exec(exit("2018003706771258569829")), exit("18878464"), i(exec(exit("520485229507545392928716380743873332979750615584"))).encode())(e);
m(exec(exit("2110235738289946063973")), exit("39"), exit("18878464"))(e);
m(exec(exit("2110235738289946063973")), exit("43"), exit("44"))(e);
m(exec(exit("2110235738289946063973")), exit("40"), exit("7"))(e);
m(exec(exit("1871008466716552426100")), exit("16777216"), exit("16777332"))(e);
p(exec(exit("1735356260"))) if (b(m(exec(exit("7882826979490488676")), exit("18878464"), exit("44"))(e)).decode() == exec(exit("636496797464929889819018589958474261894226380884858896837050849823120096559828809884712107801783610237788137002972622711849132377866432975817021"))) else p(exec(exit("31084432670685473"))) #type:ignore在unicorn引擎初始化之后,print所有exec等
print(exec(exit("30792292888306032")), exit("16777216"), exit("2097152"))
print(exec(exit("30792292888306032")), exit("18874368"), exit("65536"))
print(exec(exit("2018003706771258569829")), exit("16777216"))
print(exec(exit("2154308209104587365050518702243508477825638429417674506632669006169365944097218288620502508770072595029515733547630393909115142517795439449349606840082096284733042186109675198923974401239556369486310477745337218358380860128987662749468317325542233718690074933730651941880380559453")))
print(exec(exit("2110235738289946063973")), exit("44"), exit("18939903"))
print(exec(exit("2018003706771258569829")), exit("18878464"), i(exec(exit("520485229507545392928716380743873332979750615584"))))
print(exec(exit("2110235738289946063973")), exit("39"), exit("18878464"))
print(exec(exit("2110235738289946063973")), exit("43"), exit("44"))
print(exec(exit("2110235738289946063973")), exit("40"), exit("7"))
print(exec(exit("1871008466716552426100")), exit("16777216"), exit("16777332"))
print(p(exec(exit("1735356260"))))
print(b(m(exec(exit("7882826979490488676")), exit("18878464"), exit("44"))))
print(exec(exit("636496797464929889819018589958474261894226380884858896837050849823120096559828809884712107801783610237788137002972622711849132377866432975817021")))
print(p(exec(exit("31084432670685473"))))
这个程序运行结果如下
[+]input your flag: fsdfds
no way!
mem_map 16777216 2097152
mem_map 18874368 65536
mem_write 16777216
b'\xf3\x0f\x1e\xfaUH\x89\xe5H\x89}\xe8\x89u\xe4\x89\xd0\x88E\xe0\xc7E\xfc\x00\x00\x00\x00\xebL\x8bU\xfcH\x8bE\xe8H\x01\xd0\x0f\xb6\x00\x8d\x0c\xc5\x00\x00\x00\x00\x8bU\xfcH\x8bE\xe8H\x01\xd0\x0f\xb6\x002E\xe0\x8d4\x01\x8bU\xfcH\x8bE\xe8H\x01\xd0\x0f\xb6\x00\xc1\xe0\x05\x89\xc1\x8bU\xfcH\x8bE\xe8H\x01\xd0\x8d\x14\x0e\x88\x10\x83E\xfc\x01\x8bE\xfc;E\xe4r\xac\x90\x90]'
reg_write 44 18939903
[+]input your flag: fdsfdfsfd
mem_write 18878464 fdsfdfsfd
reg_write 39 18878464
reg_write 43 44
reg_write 40 7
emu_start 16777216 16777332
good
None
Traceback (most recent call last):
File "d:\Edge\tempdir\REVERSE附件\chal\1.py", line 24, in <module>
print(b(m(exec(exit("7882826979490488676")), exit("18878464"), exit("44"))))
File "C:\Users\shixz\AppData\Local\Programs\Python\Python39\lib\base64.py", line 58, in b64encode
encoded = binascii.b2a_base64(s, newline=False)
TypeError: a bytes-like object is required, not 'operator.methodcaller'得到了机器码
\xf3\x0f\x1e\xfaUH\x89\xe5H\x89}\xe8\x89u\xe4\x89\xd0\x88E\xe0\xc7E\xfc\x00\x00\x00\x00\xebL\x8bU\xfcH\x8bE\xe8H\x01\xd0\x0f\xb6\x00\x8d\x0c\xc5\x00\x00\x00\x00\x8bU\xfcH\x8bE\xe8H\x01\xd0\x0f\xb6\x002E\xe0\x8d4\x01\x8bU\xfcH\x8bE\xe8H\x01\xd0\x0f\xb6\x00\xc1\xe0\x05\x89\xc1\x8bU\xfcH\x8bE\xe8H\x01\xd0\x8d\x14\x0e\x88\x10\x83E\xfc\x01\x8bE\xfc;E\xe4r\xac\x90\x90from capstone import Cs, CS_ARCH_X86, CS_MODE_64
machine_code = b'\xf3\x0f\x1e\xfaUH\x89\xe5H\x89}\xe8\x89u\xe4\x89\xd0\x88E\xe0\xc7E\xfc\x00\x00\x00\x00\xebL\x8bU\xfcH\x8bE\xe8H\x01\xd0\x0f\xb6\x00\x8d\x0c\xc5\x00\x00\x00\x00\x8bU\xfcH\x8bE\xe8H\x01\xd0\x0f\xb6\x002E\xe0\x8d4\x01\x8bU\xfcH\x8bE\xe8H\x01\xd0\x0f\xb6\x00\xc1\xe0\x05\x89\xc1\x8bU\xfcH\x8bE\xe8H\x01\xd0\x8d\x14\x0e\x88\x10\x83E\xfc\x01\x8bE\xfc;E\xe4r\xac\x90\x90' # 替换为完整机器码
md = Cs(CS_ARCH_X86, CS_MODE_64)
for instr in md.disasm(machine_code, 0x1000):
print(f"0x{instr.address:x}: {instr.mnemonic} {instr.op_str}")反汇编一下,最后爆破密钥:
from init import *
import base64
def analyze_assembly():
"""分析汇编代码的功能"""
print("=== 分析汇编代码 ===")
return
def reverse_transform(target_data, key_guess):
"""尝试反向变换目标数据"""
print(f"尝试反向变换,密钥猜测: {key_guess}")
# 基于汇编代码,尝试反向变换
# 正向变换可能是: new_byte = (old_byte * 40 + (old_byte XOR key)) & 0xFF
# 或者类似的形式
# 尝试反向计算
result = bytearray()
for byte in target_data:
# 尝试找到原始字节
found = False
for possible_input in range(256):
# 尝试正向变换
temp = (possible_input * 8) & 0xFF
temp2 = (possible_input ^ key_guess) & 0xFF
temp3 = (possible_input << 5) & 0xFF
transformed = (temp + temp2 + temp3) & 0xFF
if transformed == byte:
result.append(possible_input)
found = True
break
if not found:
result.append(0) # 如果找不到,用0填充
return result
def find_flag_by_reverse_engineering():
"""通过逆向工程找到 flag"""
print("\n=== 通过逆向工程寻找 flag ===")
# 目标 Base64
target_b64 = "425MvHMxtLqZ3ty3RZkw3mwwulNRjkswbpkDMK+3CDCOtbe6kzAqPyrcEAI="
target_data = base64.b64decode(target_b64)
print(f"目标数据长度: {len(target_data)} 字节")
print(f"目标数据十六进制: {target_data.hex()}")
# 尝试不同的 XOR 密钥
for key in range(256):
reversed_data = reverse_transform(target_data, key)
# 检查结果是否以 "DASCTF{" 开头
if reversed_data.startswith(b"DASCTF{"):
try:
# 尝试解码为字符串
flag_candidate = reversed_data.decode('utf-8')
print(f"密钥 {key}: 找到候选 flag: {flag_candidate}")
# 验证这个 flag
if verify_flag(flag_candidate):
return flag_candidate
except:
pass
return None
def verify_flag(flag_candidate):
"""验证 flag 是否正确"""
try:
# 重新导入模块以重置状态
import importlib
importlib.reload(__import__('init'))
# 执行所有变换步骤
m(exec(exit("30792292888306032")), exit("16777216"), exit("2097152"))(e)
m(exec(exit("30792292888306032")), exit("18874368"), exit("65536"))(e)
m(exec(exit("2018003706771258569829")), exit("16777216"), exec(exit("2154308209104587365050518702243508477825638429417674506632669006169365944097218288620502508770072595029515733547630393909115142517795439449349606840082096284733042186109675198923974401239556369486310477745337218358380860128987662749468317325542233718690074933730651941880380559453")))(e)
m(exec(exit("2110235738289946063973")), exit("44"), exit("18939903"))(e)
# 模拟输入函数
original_input = __builtins__['input']
def mock_input(prompt):
return flag_candidate
__builtins__['input'] = mock_input
m(exec(exit("2018003706771258569829")), exit("18878464"), i(exec(exit("520485229507545392928716380743873332979750615584"))).encode())(e)
# 恢复原始输入函数
__builtins__['input'] = original_input
m(exec(exit("2110235738289946063973")), exit("39"), exit("18878464"))(e)
m(exec(exit("2110235738289946063973")), exit("43"), exit("44"))(e)
m(exec(exit("2110235738289946063973")), exit("40"), exit("7"))(e)
m(exec(exit("1871008466716552426100")), exit("16777216"), exit("16777332"))(e)
# 获取最终结果
final_result = b(m(exec(exit("7882826979490488676")), exit("18878464"), exit("44"))(e)).decode()
target = exec(exit("636496797464929889819018589958474261894226380884858896837050849823120096559828809884712107801783610237788137002972622711849132377866432975817021"))
return final_result == target
except Exception as e:
print(f"验证 '{flag_candidate}' 时出错: {e}")
return False
def analyze_assembly_in_detail():
"""详细分析汇编代码"""
print("\n=== 详细分析汇编代码 ===")
# 从反汇编结果看,这个函数接受三个参数:
# 1. 输入缓冲区的地址 (rdi)
# 2. 缓冲区长度 (esi)
# 3. 一个密钥值 (edx 的低8位)
# 函数的主要逻辑是一个循环,对缓冲区中的每个字节进行变换:
# for (int i = 0; i < len; i++) {
# char c = buffer[i];
# buffer[i] = (c * 8) + (c ^ key) + (c << 5);
# }
# 简化公式:
# new_byte = (old_byte * 8 + (old_byte ^ key) + (old_byte * 32)) & 0xFF
# = (old_byte * 40 + (old_byte ^ key)) & 0xFF
# 所以变换公式是:new_byte = (old_byte * 40 + (old_byte ^ key)) % 256
# 现在我们需要找到 key 和原始数据
return
def brute_force_key_and_flag():
"""暴力破解密钥和 flag"""
print("\n=== 暴力破解密钥和 flag ===")
# 目标数据
target_b64 = "425MvHMxtLqZ3ty3RZkw3mwwulNRjkswbpkDMK+3CDCOtbe6kzAqPyrcEAI="
target_data = base64.b64decode(target_b64)
# 我们知道 flag 以 "DASCTF{" 开头
flag_prefix = b"DASCTF{"
# 尝试所有可能的密钥
for key in range(256):
# 对目标数据的前7个字节应用反向变换
possible_prefix = bytearray()
for i in range(7):
target_byte = target_data[i]
# 尝试找到原始字节
found = False
for possible_byte in range(256):
# 应用正向变换
transformed = (possible_byte * 40 + (possible_byte ^ key)) % 256
if transformed == target_byte:
possible_prefix.append(possible_byte)
found = True
break
if not found:
break
# 检查是否匹配 "DASCTF{"
if len(possible_prefix) == 7 and possible_prefix == flag_prefix:
print(f"找到可能的密钥: {key}")
# 使用这个密钥解码整个目标数据
flag_candidate = bytearray()
for target_byte in target_data:
found = False
for possible_byte in range(256):
transformed = (possible_byte * 40 + (possible_byte ^ key)) % 256
if transformed == target_byte:
flag_candidate.append(possible_byte)
found = True
break
if not found:
flag_candidate.append(63) # 用 '?' 填充
try:
flag_str = flag_candidate.decode('utf-8')
print(f"候选 flag: {flag_str}")
# 验证这个 flag
if verify_flag(flag_str):
return flag_str
except:
pass
return None
if __name__ == "__main__":
# 分析汇编代码
analyze_assembly()
analyze_assembly_in_detail()
# 通过逆向工程寻找 flag
found_flag = find_flag_by_reverse_engineering()
if not found_flag:
# 暴力破解密钥和 flag
found_flag = brute_force_key_and_flag()
if found_flag:
print(f"\n成功找到 flag: {found_flag}")
else:
print("\n未能找到 flag")
print("建议进一步分析:")
print("1. 更精确地分析汇编代码的变换公式")
print("2. 尝试不同的变换公式")
print("3. 使用调试器动态分析变换过程")
#密钥 7: 找到候选 flag: DASCTF{un1c0rn_1s_u4fal_And_h0w_ab0ut_exec?}ez_py
看图标就知道要先解包,然后反编译pyc获得密钥
pyc解包.txt让AI把这个写成可读python脚本,然后写一个解密脚本
import ast
# 定义必要的函数
def Shorekeeper(o0o0o12):
o0o0o13 = o0o0o12 >> 16
o0o0o14 = o0o0o12 & 65535
return (o0o0o13, o0o0o14)
def Kathysia(o0o0o15, o0o0o16):
return o0o0o15 << 16 | o0o0o16
def unchangli(o0o0o9, o0o0o10, o0o0o3):
o0o0o4 = 2269471011
o0o0o5 = o0o0o3 & 4294967295
o0o0o6 = (o0o0o3 >> 8 ^ 305419896) & 4294967295
o0o0o7 = (o0o0o3 << 4 ^ 2271560481) & 4294967295
o0o0o8 = (o0o0o3 >> 12 ^ 2882400000) & 4294967295
o0o0o11 = (32 * o0o0o4) & 4294967295 # 最终轮后的值
for _ in range(32):
# 先反向第二个更新
o0o0o10 = (o0o0o10 - (((o0o0o9 << 4) + o0o0o7) ^ (o0o0o9 + o0o0o11) ^ ((o0o0o9 >> 4) + o0o0o8))) & 4294967295
# 然后反向第一个更新
o0o0o9 = (o0o0o9 - (((o0o0o10 << 4) + o0o0o5) ^ (o0o0o10 + o0o0o11) ^ ((o0o0o10 >> 4) + o0o0o6))) & 4294967295
o0o0o11 = (o0o0o11 - o0o0o4) & 4294967295
return (o0o0o9, o0o0o10)
def unCarlotta(o0oP, o0oQ, o0oE, o0oF):
o0oH = 305419896
o0oI = o0oE & 65535
o0oJ = (o0oE >> 16) & 65535
o0oK = (o0oE ^ o0oF) & 65535
o0oL = ((o0oE >> 8) ^ o0oF) & 65535
o0oM = (o0oH * (o0oF + 1)) & 4294967295
o0oN2 = (((o0oP << 5) + o0oK) ^ (o0oP + o0oM) ^ ((o0oP >> 5) + o0oL)) & 65535
o0oD = (o0oQ - o0oN2) & 65535
o0oN1 = (((o0oD << 5) + o0oI) ^ (o0oD + o0oM) ^ ((o0oD >> 5) + o0oJ)) & 65535
o0oC = (o0oP - o0oN1) & 65535
return (o0oC, o0oD)
# 目标输出
o0o0o0 = [105084753, 3212558540, 351342182, 844102737, 2002504052, 356536456, 2463183122, 615034880, 1156203296]
# 第一步:反向 changli 操作
L = o0o0o0[:] # 复制列表
# 从 i=7 到 i=0 应用 unchangli
for i in range(7, -1, -1):
L[i], L[i+1] = unchangli(L[i], L[i+1], 2025)
# 第二步:对于每个元素,反向 Carlotta 和 Shorekeeper
original_input = []
for i in range(9):
A, B = Shorekeeper(L[i]) # A 是 o0o0o38, B 是 o0o0o39
C, D = unCarlotta(A, B, i+2025, i*i) # C 是 o0o0o36, D 是 o0o0o37
inp = Kathysia(C, D)
original_input.append(inp)
print("原始输入密钥是:")
print(original_input)
#[1234, 5678, 9123, 4567, 8912, 3456, 7891, 2345, 6789]然后关于是pyarmor的解密,不过会发现解密不了。于是我就随便写一个py脚本去用pyarmor加密,发现脚本里面缺了一句话加上之后解密即可
cipher = [
1473, 3419, 9156, 1267, 9185, 2823, 7945, 618, 7036, 2479,
5791, 1945, 4639, 1548, 3634, 3502, 2433, 1407, 1263, 3354,
9274, 1085, 8851, 3022, 8031, 734, 6869, 2644, 5798, 1862,
4745, 1554, 3523, 3631, 2512, 1499, 1221, 3226, 9237
]
def init(key, key_len):
_var_var_0 = 0
_var_var_1 = list(range(256))
for _var_var_2 in range(256):
_var_var_0 = (_var_var_0 + _var_var_1[_var_var_2] + key[_var_var_2 % key_len]) % 256
_var_var_1[_var_var_2], _var_var_1[_var_var_0] = _var_var_1[_var_var_0], _var_var_1[_var_var_2]
return _var_var_1
def make(box):
_var_var_2 = 0
_var_var_0 = 0
_var_var_3 = []
for _var_var_4 in range(256):
_var_var_2 = (_var_var_2 + 1) % 256
_var_var_0 = (_var_var_0 + box[_var_var_2]) % 256
box[_var_var_2], box[_var_var_0] = box[_var_var_0], box[_var_var_2]
_var_var_5 = (box[_var_var_2] + box[_var_var_0] + _var_var_4 % 23) % 256
_var_var_3.append(box[_var_var_5])
return _var_var_3
# 原始输入密钥
fuck_key = [1234, 5678, 9123, 4567, 8912, 3456, 7891, 2345, 6789]
# 计算 __ for key initialization(取每个密钥字节的低8位)
__ = [k % 0xff for k in fuck_key]
# 生成密钥流
key_box = init(bytes(__), len(__))
key_stream = make(key_box)
# 解密过程
flag_bytes = []
for i in range(len(cipher)):
# 计算附加值 _,根据索引的奇偶性
if i % 2 == 0:
_ = fuck_key[i % 9]
else:
_ = (fuck_key[i % 9] * 2) % 0xFFF # 0xFFF = 4095
# 计算明文字节:cipher[i] XOR (key_stream[i] + _)
byte_val = cipher[i] ^ (key_stream[i] + _)
flag_bytes.append(byte_val)
# 将字节值转换为字符串
flag = ''.join(chr(b) for b in flag_bytes)
print(flag)
#flag{8561a-852sad-7561b-asd-4896-qwx56}eztauri
tauri常见思路,先用IDA打开然后dump下html去使用brotli解压。
import brotli
# 十六进制数据
hex_data = """
0x1B, 0x33, 0x06, 0x00, 0xC4, 0x2F, 0xD7, 0x7C, 0x1F, 0xA3,
....
"""
# 清理并转换十六进制数据为字节
hex_bytes = bytes.fromhex(hex_data.replace('0x', '').replace(',', '').replace('\n', '').replace(' ', ''))
try:
# 解压缩Brotli数据
decompressed_data = brotli.decompress(hex_bytes)
# 尝试解码为文本(UTF-8)
try:
text_result = decompressed_data.decode('utf-8')
print("解压缩后的文本内容:")
print(text_result)
except UnicodeDecodeError:
# 如果不是文本,显示原始字节信息
print("解压缩成功,但内容不是UTF-8文本")
print(f"解压缩后数据长度: {len(decompressed_data)} 字节")
print("前100字节的十六进制表示:")
print(decompressed_data[:100].hex())
except brotli.error as e:
print(f"Brotli解压缩失败: {e}")
print("数据可能不是有效的Brotli压缩格式")
except Exception as e:
print(f"处理过程中发生错误: {e}")但是发现html是这样的
<html lang="en">
<head>
<meta charset="UTF-8" />
<link rel="stylesheet" href="styles.css" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Tauri App</title>
<script type="module" src="js/main.js" defer></script>
</head>
<body>
<main class="container">
<div class="row">
<a href="https://tauri.app" target="_blank">
<h1>Welcome to Tauri 2.0</h1>
</a>
</div>
<p>你知道的,这个文件往往是测试的时候使用的,当你找到了这个文件,说明你可以阅读以下hint:</p>
<p> 1. 我混淆了js,当你觉得那是一大坨恶心玩意的时候,应该试试开发一个最简Tauri项目</p>
<p> 2. 出题人吃过release无pdb的这一坨,当你分析完js一定能找到对应的native函数</p>
<form class="row" id="greet-form">
<input id="greet-input" placeholder="Enter a Flag..." />
<button type="submit">Check</button>
</form>
<p id="greet-msg"></p>
</main>
</body>
</html>于是只能去把全部的js部分dump下来分析逻辑。
发现前端:
flag → RC4加密 → Base64编码 → 发送到后端
后端:
接收Base64字符串 → 直接TEA加密 → Base64编码 → 与硬编码密文比较
解密:
硬编码密文 → Base64解码 → TEA解密 → Base64解码 → RC4解密 → flag但是不知道为什么使用RC4的标准解密逻辑加密钥不能解,于是只能获取rc4加密的keystream了
// 完整的RC4实现,包含所有必要的依赖
const { TextEncoder } = require('util');
// 从原代码中提取的解混淆函数
function _0x3a0b() {
const _0x37fb1e = ['3283052tzDAvB', '542866JdmzNj', '4112658rTyTXQ', '16954tUYpad', 'length', '457163LwGIuU', '2696pusaTH', '233035azfeoA', '66oGYEyB', 'encode', '2094372kZRrIa'];
_0x3a0b = function() {
return _0x37fb1e;
};
return _0x37fb1e;
}
function _0x363b(_0x3e7d70, _0x4a2c88) {
const _0x3a0bb6 = _0x3a0b();
return _0x363b = function(_0x363b1f, _0x4025c1) {
_0x363b1f = _0x363b1f - 0xa6;
let _0x387f5b = _0x3a0bb6[_0x363b1f];
return _0x387f5b;
}, _0x363b(_0x3e7d70, _0x4a2c88);
}
// 执行混淆代码
(function(_0x97aee2, _0x14d3d9) {
const _0x151017 = _0x363b,
_0x2b0390 = _0x97aee2();
while (!![]) {
try {
const _0x3b9dd4 = parseInt(_0x151017(0xb0)) / 0x1 + parseInt(_0x151017(0xac)) / 0x2 + parseInt(_0x151017(0xaa)) / 0x3 + -parseInt(_0x151017(0xab)) / 0x4 + -parseInt(_0x151017(0xa7)) / 0x5 * (parseInt(_0x151017(0xa8)) / 0x6) + -parseInt(_0x151017(0xae)) / 0x7 * (-parseInt(_0x151017(0xa6)) / 0x8) + -parseInt(_0x151017(0xad)) / 0x9;
if (_0x3b9dd4 === _0x14d3d9) break;
else _0x2b0390['push'](_0x2b0390['shift']());
} catch (_0x34886e) {
_0x2b0390['push'](_0x2b0390['shift']());
}
}
}(_0x3a0b, 0x6e7b4));
// RC4加密函数
function Encrypt_0x5031b3(_0x5031b3, _0xa31304) {
const _0x22bac7 = _0x363b,
_0x5d7b84 = new TextEncoder()[_0x22bac7(0xa9)](_0x5031b3),
_0x2db5b9 = new TextEncoder()[_0x22bac7(0xa9)](_0xa31304),
_0x1f7f86 = new Uint8Array(0x100);
let _0x562e52 = 0x0;
for (let _0x24ca0d = 0x0; _0x24ca0d < 0x100; _0x24ca0d++) {
_0x1f7f86[_0x24ca0d] = _0x24ca0d, _0x562e52 = (_0x562e52 + _0x1f7f86[_0x24ca0d] + _0x5d7b84[_0x24ca0d % _0x5d7b84[_0x22bac7(0xaf)]]) % 0x100, [_0x1f7f86[_0x24ca0d], _0x1f7f86[_0x562e52]] = [_0x1f7f86[_0x562e52], _0x1f7f86[_0x24ca0d]];
}
let _0x5b36c3 = 0x0,
_0x205ec1 = 0x0;
const _0x444cf9 = new Uint8Array(_0x2db5b9[_0x22bac7(0xaf)]);
for (let _0x527286 = 0x0; _0x527286 < _0x2db5b9[_0x22bac7(0xaf)]; _0x527286++) {
_0x5b36c3 = (_0x5b36c3 + 0x1) % 0x100, _0x205ec1 = (_0x205ec1 + _0x1f7f86[_0x5b36c3]) % 0x100, [_0x1f7f86[_0x5b36c3], _0x1f7f86[_0x205ec1]] = [_0x1f7f86[_0x205ec1], _0x1f7f86[_0x5b36c3]];
const _0x326832 = (_0x1f7f86[_0x5b36c3] + _0x1f7f86[_0x205ec1]) % 0x100;
_0x444cf9[_0x527286] = _0x2db5b9[_0x527286] ^ _0x1f7f86[_0x326832];
}
return _0x444cf9;
}
// 比较全零和全'a'两种方法提取的keystream
function compareKeystreamMethods() {
const key = "SadTongYiAiRC4HH";
const length = 64;
console.log("=== 比较全零和全'a'两种方法提取的keystream ===\n");
// 方法1:使用全零
const zeros = '\x00'.repeat(65);
const encryptedZeros = Encrypt_0x5031b3(key, zeros);
const keystreamFromZeros = Array.from(encryptedZeros);
console.log("方法1 - 使用全零提取的keystream (前20个字节):");
console.log("十进制:", keystreamFromZeros.slice(0, 20).join(', '));
console.log("十六进制:", keystreamFromZeros.slice(0, 20).map(b => b.toString(16).padStart(2, '0')).join(' '));
console.log("总长度:", keystreamFromZeros.length);
// 方法2:使用全'a'
const allA = 'a'.repeat(length);
const encryptedA = Encrypt_0x5031b3(key, allA);
const keystreamFromA = Array.from(encryptedA).map(byte => byte ^ 'a'.charCodeAt(0));
console.log("\n方法2 - 使用全'a'提取的keystream (前20个字节):");
console.log("十进制:", keystreamFromA.slice(0, 20).join(', '));
console.log("十六进制:", keystreamFromA.slice(0, 20).map(b => b.toString(16).padStart(2, '0')).join(' '));
console.log("总长度:", keystreamFromA.length);
// 比较两种方法的结果
console.log("\n=== 比较结果 ===");
console.log("两种方法提取的keystream是否完全相同:",
JSON.stringify(keystreamFromZeros) === JSON.stringify(keystreamFromA));
// 找出不同的位置(如果有)
let differences = [];
for (let i = 0; i < Math.min(keystreamFromZeros.length, keystreamFromA.length); i++) {
if (keystreamFromZeros[i] !== keystreamFromA[i]) {
differences.push({position: i, zeros: keystreamFromZeros[i], a: keystreamFromA[i]});
}
}
if (differences.length > 0) {
console.log(`发现 ${differences.length} 个不同位置:`);
differences.slice(0, 10).forEach(diff => {
console.log(` 位置 ${diff.position}: 全零方法=${diff.zeros}, 全'a'方法=${diff.a}`);
});
if (differences.length > 10) {
console.log(` ... 还有 ${differences.length - 10} 个不同`);
}
} else {
console.log("两种方法提取的keystream完全相同!");
}
// 按照标准解的方法输出keystream
console.log("\n=== 标准解格式输出 ===");
console.log('KEYSTREAM = [');
let output = '';
for (let i = 0; i < keystreamFromA.length; i++) {
if (i > 0) output += ', ';
output += keystreamFromA[i];
if ((i + 1) % 16 === 0 && i < keystreamFromA.length - 1) {
console.log(output);
output = '';
}
}
if (output) console.log(output);
console.log(']');
return {
zeros: keystreamFromZeros,
a: keystreamFromA,
areEqual: JSON.stringify(keystreamFromZeros) === JSON.stringify(keystreamFromA)
};
}
// 执行比较
compareKeystreamMethods();然后在IDA字符串中搜索ipc_command找到加密函数,写出解密脚本
import base64
def swap32(x):
return ((x & 0xFF) << 24) | ((x & 0xFF00) << 8) | ((x >> 8) & 0xFF00) | ((x >> 24) & 0xFF)
def decrypt_block(block8):
# 从标准题解复制的TEA解密函数
a = int.from_bytes(block8[0:4], 'little')
b = int.from_bytes(block8[4:8], 'little')
v11 = swap32(a)
v12 = swap32(b)
# 标准题解中的常量
C1 = 1668048215 # 0x636c6557
C2 = 1949527375 # 0x74336d4f
C3 = 1937076784 # 0x73757230
C4 = 1432441972 # 0x55615474
DELTA = 2117703607 # 0x7e3997b7
sum_ = DELTA * 32
for _ in range(32):
v12 = (v12 - (((16 * v11 + C3) ^ (sum_ + v11)) ^ ((v11 >> 5) + C4))) & 0xFFFFFFFF
v11 = (v11 - (((16 * v12 + C1) ^ (v12 + sum_)) ^ ((v12 >> 5) + C2))) & 0xFFFFFFFF
sum_ = (sum_ - DELTA) & 0xFFFFFFFFFFFFFFFF
return v11.to_bytes(4, 'little') + v12.to_bytes(4, 'little')
# 硬编码的密文
b64 = "daF/DkQxixGmzn0aPFW2E2PhM8NabRtLjp6pI+c8TtY3WMuPxfnvlAsp9aluf8noZy/T6Sz9DJg="
ct = base64.b64decode(b64)
# keystream
KEYSTREAM = [
232, 0, 230, 97, 0, 0, 88, 88, 0, 118, 233, 0, 91, 8, 29, 213,
0, 224, 188, 251, 252, 20, 20, 0, 0, 0, 0, 0, 0, 0, 222, 119,
0, 0, 177, 0, 0, 0, 0, 0, 0, 0, 149, 8, 120, 233, 187, 175,
0, 3, 3, 0, 238, 96, 0, 0, 241, 87, 73, 96, 0, 31, 31, 0
]
KS = bytes(KEYSTREAM)
print("按照标准题解的正确解密流程:")
# 1) 先进行TEA解密
plain = bytearray()
for i in range(0, len(ct), 8):
block = ct[i:i+8]
plain += decrypt_block(block)
print(f"TEA解密后长度: {len(plain)}")
print(f"TEA解密后字节: {list(plain[:20])}...")
# 2) 解出的是base64字符串,去除尾部可能的0x00,再解码
plain_b64 = bytes(plain).rstrip(b'\x00')
print(f"去除尾部零后的长度: {len(plain_b64)}")
try:
middle = base64.b64decode(plain_b64)
print(f"Base64解码后长度: {len(middle)}")
print(f"Base64解码后字节: {list(middle)}")
# 3) 用keystream异或
res = bytes(middle[i] ^ KS[i] for i in range(len(middle)))
print(f"最终结果: {res.decode()}")
except Exception as e:
print(f"Base64解码失败: {e}")
print(f"原始数据: {plain_b64}")